2018 Datathon Experience
January 29, 2018
On January 27th I had the privilege of taking part in the Citadel Data Open at UofT. The datathon was a mix between a business case competition and a hackathon. Participants were given a data set at the start of the day and asked to come up with insights/recommendations based on the it. For this competition it was transportation data for six major cities from Geotab.
Having participated in business case competitions before, I had some sense of how the day would go, but what I was unprepared for was how open-ended and unstructured the task was. In business case competitions usually there is a clearly defined question/problem to address. In this datathon it was almost the opposite. A significant part of our team’s day was spent trying to figure out what problems even existed. It was a very interesting process which took the form of hypothesizing which relationships we might find in the data, and then pursuing those ideas to see if the data actually backed them up.
I was lucky to be on a team with two Computer Science PhDs and one Statistics PhD. I was a bit of the odd one out coming from a business background and having yet to take a course in Machine Learning. It was a great learning experience to hear the perspectives of my teammates about how to approach the problem. What I did come to appreciate from the competition was that one can have the best machine learning model out there, but if you are addressing the wrong question, or your inferences are based on faulty assumptions, your analysis is not worth much.
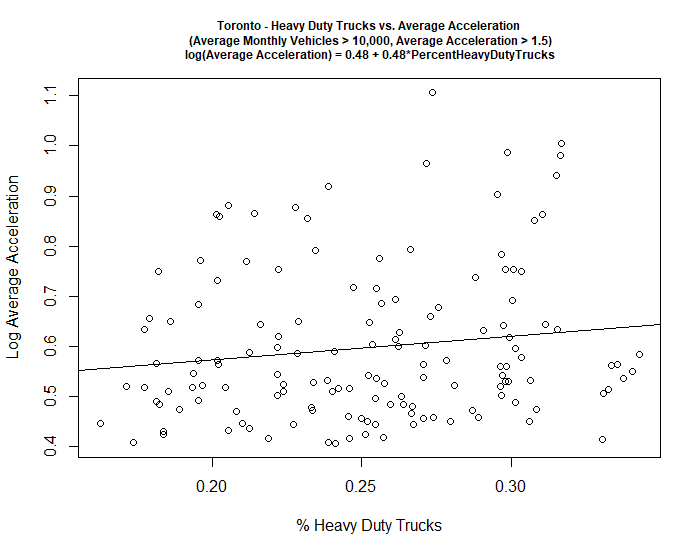
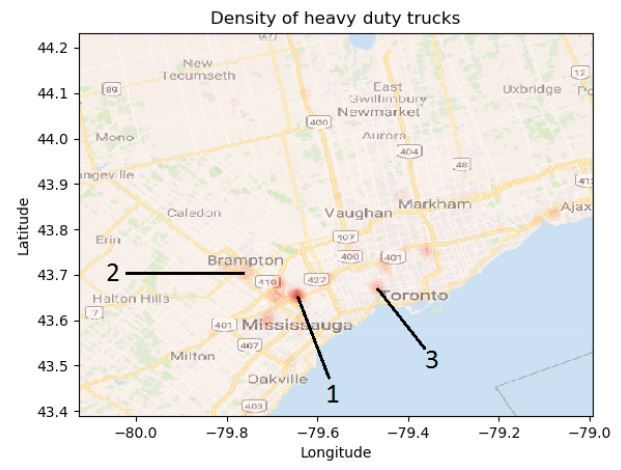
Our team’s recommendation was that Toronto should consider banning trucks during rush hour on the 400 series highways to decrease congestion (something that has actually been floated in the past). Unfortunately we did not come in the top three teams. When commenting on how teams fared overall the judges noted that since the data for the competition was from a fleet management company (i.e. cars/trucks) the data was likely to be biased in some manner about trucks so the inferences one derives from the data would also biased about trucks. I have to admit it was a little frustrating to hear this (it felt a bit like a ‘gotcha’), especially since some of the richest data in the dataset was related to trucks. A lesson learnt for the future is to be more critical in assessing the source of the data when looking at a problem.
I was happy to have been able to contribute to our team with some of the basic R and linear regression I have learnt this year at school. The competition was a great learning experience, and makes me excited as I continue my studies in statistics. I am looking forward to tackling more data-related challenges like these in the future! Big shout out to Citadel, Correlation One, and my teammates for the great experience.
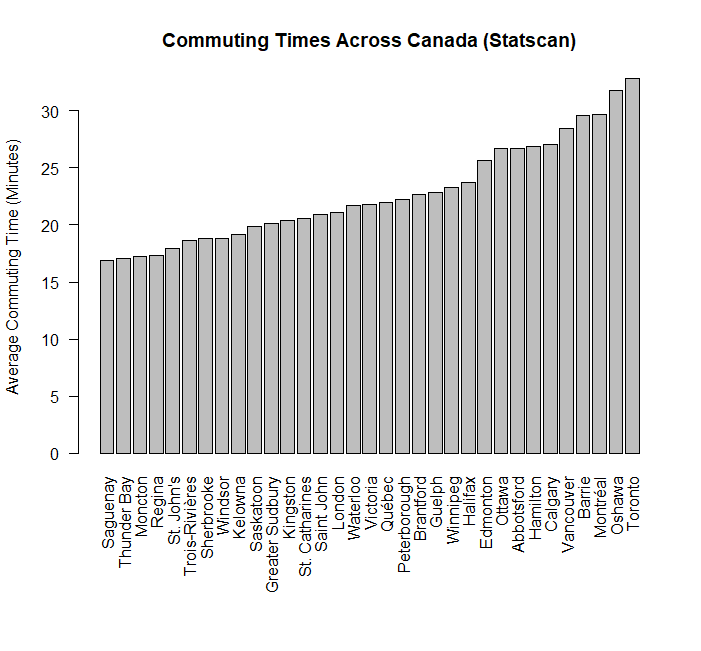
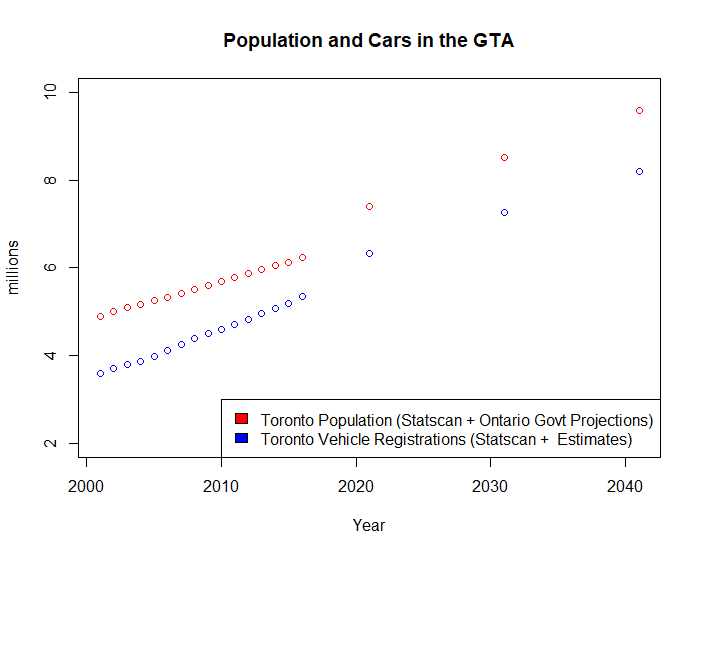
A few charts (map is from my teammate Tian) and link to some of the code I wrote on Github.